This really bothered me, once I was forced to think about it.
I had previously assumed (wrongly) that the unexpectedly high second hop RTTs (and similar subsequent) values across our service provider were due to low priority in processing ICMP/tracereoute packets (many routers treat these things as low priority, for various good reasons).
That was a good enough "explanation" that I'd not really thought beyond that (or, it hadn't bothered me enough to get properly intrigued).
And I hadn't done pings to those intermediate hosts, and compared them side-by-side.
Shame on me.
And sure, ping and traceroute by default use different protocols (until you do traceroute -I).
But that's not it either.
Maybe traceroute sends so many more packets at a time than a ping that you hit a rate limit (1 per 500ms is a rate limit on some routers)? ping is ~1 per second; traceroute fires out loads in groups of 3 spaced per hop (well, TTL increment) quite closely together.
That's not it either.
Maybe a firewall was breaking things?
But no, that makes no sense; both in this case are ICMP Echo, and it's unlikely they're going to treat ICMP Echo to destination A differently to Destination B on the Internet.
I'm familiar with a bunch of other common pitfalls with interpreting traceroutes, but this wasn't one of those.
As someone who really likes networking, this should have prompted investigation long ago, but it's not bothered me enough to go work it out (aka "I had more pressing concerns").
Until someone said "Explain this" and presented a side-by-side ping and traceroute with Odd Results...
Then, of course, you start THINKING about the problem, and, if you're not familiar with the underlying configuration and particularly some potential configurations of service provider networks outside your own control will probably cause you to pull your hair out.
So why...?
Basically, what this revealed was a big (MPLS shaped) hole in my knowledge of (large) Service Provider network routing.
So, back to the drawing board, and some useful background.
If you're in this situation, and you do a traceroute -I to a host, it's effectively (but not exactly) pinging (ICMP Echo) each host along the path - but when you manually ping (which should [and does] use the same packet type and give you the same answer) you (may) get a wildly different result.
This is actually two problems - a) why are there a lot of traceroute hops with more or less the same latency and b) why is ping to (at least some of) those hops so much faster?
Note that using normal Unix traceroute (which uses UDP packets with increasing TTL) will give you similar results - but we want to discount any influence of protocol - so let's stick to ICMP Echo for both ping and traceroute to minimise some possible sources of difference.
Now go back and manually ping each hop IP as exposed by traceroute.
Compare the traceroute time values to each hop's direct ping RTTs.
Anything Odd?
(NB you will not see this effect, or you may only see a) unless you have this specific network configuration affecting you).
You would expect (with some modest variability) similar results for both tests - but not a difference of tens of milliseconds between the two; you would also expect an increase along the path, not a whole bunch of more or less the same figures.
But no, there are differences of tens of milliseconds involved. And a whole bunch of routers with more or less the same RTT value even though they're geographically quite widely dispersed.
That is pretty weird if you understand what traceroute -I and ping do, and have a mental map of where the packets are going and the expected speed-of-light-in-glass rtt for those paths.
Of course, if you really really understand modern networks, there are some other things to consider. Eventually, I begged for the answer.
We've not verified this with the upstream ISP, but research into this seems to suggest it's really the by far the best explanation for the phenomenon:
MPLS (sometimes) breaks some common expectations/assumptions.
Here are some values, so you can see what I'm talking about.
 |
| Note sudden jump to ~30ms - even though this router is just down the road (~130km away). |
I can live with 4ms to PLZ and back. But 30ms? Seems like something is "broken":
~34ms vs 4ms difference?
So why do we even want an MPLS tunnel? How dare you break my traceroutes!
MPLS has some interesting features for service provider networks (and large corporates - only one of which is L3 MPLS VPNs), which you should go and read about. I promise they're (in the end) useful to you as a customer, and you're probably using them, often without even knowing about it.
MPLS tunnels, in particular, mean that your service provider (or you in a huge network) can use less "powerful" routers (ones that can't do BGP or aren't big enough for a full internet route table) to whack customer packets across their network in interesting ways. MPLS is quick and speedy at doing this sort of thing, and is particularly useful if you want a "BGP Free MPLS Core" - which you might well do for reasons involving saving huge amounts of money, or some interesting traffic engineering options. You can then have provider routers (P) that only care about MPLS labels (aka "label switching routers" or LSRs) and have no idea about routes to all possible src/dst IP addresses wanging packets about the place for you. Provider Edge (PE) Routers are more likely to have a more complete (or even full) BGP routing table. Effectively, by design, one bonus is that switching MPLS labels is more like switching Ethernet frames than routing packets - it's likewise faster and requires cheaper hardware for the same line rate throughput (compare the cost of a 10Gb/s swich with a 10Gb/s router - I can get a 16 port 10Gb/s switch for about 10% of the price of a 24 port 10Gb/s L3 switch - this will be similar for routers). There are other costs (you usually have to manually create the tunnels by defining LSPs, for instance, but when you're talking about saving [several] zeroes on [many] routers, or using some other "must have" feature of MPLS, the Network Architect pain pays off). This also makes me think that SP-track network certs will be interesting to study.
https://forums.juniper.net/t5/Routing/what-does-quot-icmp-tunneling-quot-mean-in-mpls-vpn/td-p/164284 in particular has some very key things to help understand about what is going on. That diagram about half way down in particular is a major "a-ha!" moment.
Here is an even clearer visual:
From a customer-side network engineering point of view, tunnels of this type make Internet routing/paths (in parts) almost as hard to figure out (opaque) as L2 paths - and you can't exactly get into some random router on the Internet to troubleshoot (although on your LAN, you could figure out L2 paths by looking at MAC tables in your switches). So it's certainly something to think about. But you don't necessarily have to care about it - but remember to account for it in, for example, odd results like those shown. The ones we've seen here are semi-transparent - but some configurations can completely hide the LSRs in the middle - you might just notice a surprisingly long "hop" at some stage, but think nothing of it "oh, that must be a long distance link" (and, effectively it is, but it's not a light path - it's a label switched MPLS route with several LSR P routers involved).
Depending on the options your ISP (or some other network along the path) uses, this may or may not be a feature you see - MPLS can entirely hide topology from the end user's perspective, and for most people, there's no issue with that. However, if they elect to use icmp tunneling features, then hops can be seen, but those hops may struggle to route the packets efficiently - you get a good idea of the path, but the timings look odd.
And this is ultimately what we suspect is happening here.
I'm guessing we're seeing at least 2 MPLS tunnels there; hosts in what I think are the 2nd tunnel consistently give ~30ms direct ping results too, whereas the others in "tunnel 1" give steadily incrementing rtts - up until the router that goes back down to ~15ms - after which both ping and ICMP traceroute are ~30ms.
To my knowledge, our traffic for 8.8.8.8 normally goes from here, to PLZ, to CPT, to JNB to get to Google's GGC in Johannesburg. I suspect there are Traffic Engineering (TE) MPLS tunnels from our local PoP to Cape Town, and from Cape Town to Joburg.
But hang on a minute, why doesn't this (always) happen with Ping too? Surely that ICMP gets tunneled as well? I mean, it's called "ICMP tunneling" isn't it? And how can we explain the differences in behaviour between the "first" and "second" tunnel wrt ping and traceroute times?
Well, if you're pinging the a router directly, then it probably knows where you are (not necessarily so for others, particularly pure LSRs (P Routers), but in many SP networks, the intermediate routers may well know what's going on for their customers - at least within a "region" of some kind, but not for the global Internet), and it knows who it is - unlike a traceroute ICMP Echo which instead has a destination of the ultimate destination IP - and they're also likely to know about some of their neighbouring routers in that situation. But as far as that intermediate host router in the MPLS tunnel is concerned, the route may be entirely unknown, and it will typically spew that packet out the other end of the tunnel, (so the RTT becomes that of the tunnel endpoint that has enough routing information to return the packet).
A tracert to a generic host on the Internet is quite unlike a ping packet addressed to the router itself, which has a source and destination IP it might know how to route, particularly if the routers between itself and the PE router the customer uses have routes to the customer's prefix, but those routers (almost by definition) are not likely to have a full Internet table, so will merrily forward the TTL expired out the end of the LSP for the PE router at the other end to return (often down another LSP).
Or perhaps of course it's MUCH simpler than that - direct ping packets to at least some MPLS tunnel (P LSR) routers don't end up in the MPLS tunnel in the first place, because that destination IP (unlike ICMP traceroute to say 8.8.8.8, which is shoved into the tunnel) isn't part of the prefixes shoved into the MPLS tunnel. That would certainly explain observed behaviour in concert with different "areas" of an SP network having different routing information. Pings to later (more distant) P LSRs may end up in an MPLS tunnel, which is why some Pings end up being similar to the traceroute RTTs on all the intervening hops, whereas some are much closer to the expected "speed of light" time - and this is a function of distance, and seems moderately sane for the design off a large network from "basic principles". This, I think, lies at the heart of the much shorter pings direct to many of the routers themselves (vs much longer ICMP traceroute RTTs through the same routers). Either this paragraph or the one above explains behaviour b). I far favour this explanation, as the one above seems like gypsy magic that doesn't gel well with my understanding of routers - but it was my first "wtf is going on here" hypothesis.
With that minor brainwave (customer vs service provider vs global Internet routing), I thought "hey, what happens if I compare traceroute/ping test to another customer of our ISP"? Long story short, "it depends" and I don't know of enough customers or enough about the SP's MPLS topology to definitively work out what happens; those on the same PoP as us work as expected; those a router away also as expected; the rest, a bit of a mess and somewhat uncertain. I guess Google Moar! is in order.
It's probably easiest to just accept on the whole, MPLS tunnel routers (P LSRs) with icmp tunneling set up are going to end up appearing to "report" (an oversimplification of what's going on - your host is in charge of the timing, and it's because the packet has travelled to the end and back that it gets that longer RTT time) a lot of RTTs from the far end of the tunnel - that at least explains the observed unexpectedly long (and consistent for several widely spaced hops) traceroute behaviour (part a) of the puzzle).
I'll wireshark it to demonstrate the major differences between ICMP traceroute and ICMP ping; if you don't know wireshark, it's worth adding to your toolkit, it makes figuring stuff out quite easy:
If you see a bunch of similar ping times in a tracert, with a big jump between two hops (that isn't the result of say a transoceanic transit) and wildly different direct ping to each hop vs ICMP traceroute round trip timings(RTTs), suspect MPLS tunnels with icmp tunneling enabled.
It kind of leaves me itching to see more of the config on the service provider's routers...
It's a jump from mid-size enterprise networking knowledge levels into large Service Provider/massive enterprise networking, but it's useful to know about! That's one thing I enjoy about networks - they're fun puzzles, and there is always more to learn. Anyway, I've learnt something new and useful about interpreting Traceroute results today, and found a satisfying answer to something that's sort of bothered me for years - maybe you have too! I'll probably come back and tweak this article as I learn more about MPLS and my understanding solidifies.
 |
| Here's a ping to the same hop. Only ~4ms. That's like an order of magnitude difference from the previous result, but more plausible for something ~130km away. That is CRAZY. |
 |
| This picture about sums it up. At least until you understand what is going on. |
Digging into MPLS
MPLS has some interesting features for service provider networks (and large corporates - only one of which is L3 MPLS VPNs), which you should go and read about. I promise they're (in the end) useful to you as a customer, and you're probably using them, often without even knowing about it.
MPLS tunnels, in particular, mean that your service provider (or you in a huge network) can use less "powerful" routers (ones that can't do BGP or aren't big enough for a full internet route table) to whack customer packets across their network in interesting ways. MPLS is quick and speedy at doing this sort of thing, and is particularly useful if you want a "BGP Free MPLS Core" - which you might well do for reasons involving saving huge amounts of money, or some interesting traffic engineering options. You can then have provider routers (P) that only care about MPLS labels (aka "label switching routers" or LSRs) and have no idea about routes to all possible src/dst IP addresses wanging packets about the place for you. Provider Edge (PE) Routers are more likely to have a more complete (or even full) BGP routing table. Effectively, by design, one bonus is that switching MPLS labels is more like switching Ethernet frames than routing packets - it's likewise faster and requires cheaper hardware for the same line rate throughput (compare the cost of a 10Gb/s swich with a 10Gb/s router - I can get a 16 port 10Gb/s switch for about 10% of the price of a 24 port 10Gb/s L3 switch - this will be similar for routers). There are other costs (you usually have to manually create the tunnels by defining LSPs, for instance, but when you're talking about saving [several] zeroes on [many] routers, or using some other "must have" feature of MPLS, the Network Architect pain pays off). This also makes me think that SP-track network certs will be interesting to study.
https://forums.juniper.net/t5/Routing/what-does-quot-icmp-tunneling-quot-mean-in-mpls-vpn/td-p/164284 in particular has some very key things to help understand about what is going on. That diagram about half way down in particular is a major "a-ha!" moment.
Here is an even clearer visual:
 |
| Shamelessly stolen from the excellent https://www.slideshare.net/RichardSteenbergen/a-practical-guide-to-correctly-troubleshooting-with-traceroute |
Depending on the options your ISP (or some other network along the path) uses, this may or may not be a feature you see - MPLS can entirely hide topology from the end user's perspective, and for most people, there's no issue with that. However, if they elect to use icmp tunneling features, then hops can be seen, but those hops may struggle to route the packets efficiently - you get a good idea of the path, but the timings look odd.
And this is ultimately what we suspect is happening here.
I'm guessing we're seeing at least 2 MPLS tunnels there; hosts in what I think are the 2nd tunnel consistently give ~30ms direct ping results too, whereas the others in "tunnel 1" give steadily incrementing rtts - up until the router that goes back down to ~15ms - after which both ping and ICMP traceroute are ~30ms.
To my knowledge, our traffic for 8.8.8.8 normally goes from here, to PLZ, to CPT, to JNB to get to Google's GGC in Johannesburg. I suspect there are Traffic Engineering (TE) MPLS tunnels from our local PoP to Cape Town, and from Cape Town to Joburg.
But hang on a minute, why doesn't this (always) happen with Ping too? Surely that ICMP gets tunneled as well? I mean, it's called "ICMP tunneling" isn't it? And how can we explain the differences in behaviour between the "first" and "second" tunnel wrt ping and traceroute times?
Well, if you're pinging the a router directly, then it probably knows where you are (not necessarily so for others, particularly pure LSRs (P Routers), but in many SP networks, the intermediate routers may well know what's going on for their customers - at least within a "region" of some kind, but not for the global Internet), and it knows who it is - unlike a traceroute ICMP Echo which instead has a destination of the ultimate destination IP - and they're also likely to know about some of their neighbouring routers in that situation. But as far as that intermediate host router in the MPLS tunnel is concerned, the route may be entirely unknown, and it will typically spew that packet out the other end of the tunnel, (so the RTT becomes that of the tunnel endpoint that has enough routing information to return the packet).
A tracert to a generic host on the Internet is quite unlike a ping packet addressed to the router itself, which has a source and destination IP it might know how to route, particularly if the routers between itself and the PE router the customer uses have routes to the customer's prefix, but those routers (almost by definition) are not likely to have a full Internet table, so will merrily forward the TTL expired out the end of the LSP for the PE router at the other end to return (often down another LSP).
Or perhaps of course it's MUCH simpler than that - direct ping packets to at least some MPLS tunnel (P LSR) routers don't end up in the MPLS tunnel in the first place, because that destination IP (unlike ICMP traceroute to say 8.8.8.8, which is shoved into the tunnel) isn't part of the prefixes shoved into the MPLS tunnel. That would certainly explain observed behaviour in concert with different "areas" of an SP network having different routing information. Pings to later (more distant) P LSRs may end up in an MPLS tunnel, which is why some Pings end up being similar to the traceroute RTTs on all the intervening hops, whereas some are much closer to the expected "speed of light" time - and this is a function of distance, and seems moderately sane for the design off a large network from "basic principles". This, I think, lies at the heart of the much shorter pings direct to many of the routers themselves (vs much longer ICMP traceroute RTTs through the same routers). Either this paragraph or the one above explains behaviour b). I far favour this explanation, as the one above seems like gypsy magic that doesn't gel well with my understanding of routers - but it was my first "wtf is going on here" hypothesis.
With that minor brainwave (customer vs service provider vs global Internet routing), I thought "hey, what happens if I compare traceroute/ping test to another customer of our ISP"? Long story short, "it depends" and I don't know of enough customers or enough about the SP's MPLS topology to definitively work out what happens; those on the same PoP as us work as expected; those a router away also as expected; the rest, a bit of a mess and somewhat uncertain. I guess Google Moar! is in order.
It's probably easiest to just accept on the whole, MPLS tunnel routers (P LSRs) with icmp tunneling set up are going to end up appearing to "report" (an oversimplification of what's going on - your host is in charge of the timing, and it's because the packet has travelled to the end and back that it gets that longer RTT time) a lot of RTTs from the far end of the tunnel - that at least explains the observed unexpectedly long (and consistent for several widely spaced hops) traceroute behaviour (part a) of the puzzle).
Of course, routes change, so it's worth making sure your assumptions haven't changed in the middle of an investigation - here's the latest tracert from my windows machine; it's well worth knowing "typical" and "expected" routes from your location, but don't be too hasty to report a "fault", as your service provider knows their network better than you do...!
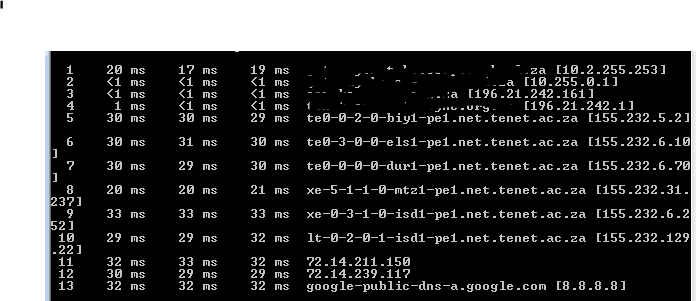 |
| Compare it with the earlier one from Ubuntu It's going the other way around the country! |
 |
| Partial Wireshark (filtered) of a ICMP Traceroute from my PC to 8.8.8.8, (tail end of tracert) followed by (highlighted packet onwards) by a Ping directly to the first ~30ms host. |
As you can see, Traceroute ICMP packets have (logically!) the destination address of the desired end host. Those MPLS tunnel routers don't know what to do with the response, so it goes out the other end, and the remote PE router sents it back, with the result that the RTTs are ~the RTT to the end of the tunnel and back again (i.e. a bunch of ~30ms RTTs); the "traditional ping" of course has a dst of the router itself, and clearly at least those in the "first" MPLS tunnel have enough route information to get directly back to me (but not with a dst of 8.8.8.8) - or, perhaps, don't go via the MPLS tunnel in the first place - those in my hypothetical second tunnel seem not to escape that fate (and that fits with routers that don't have full routing info available for the entire SP and client network prefixes, let alone global routes - but also fits with different routing depending on how things get stuffed into the tunnels).
If we think of MPLS tunnels (well, LSPs, strictly) as being unidirectional from point A (PE A) to point B (PE B), depending on which end of a tunnel you're at (and whether your P router in that tunnel has relevant routing information) may have an effect and may explain the observed differences in ping vs traceroute times; obviously, the routing tables on the MPLS tunnel routers (P routers) play a role. I'm speculating here, before going off to learn more about this stuff, but it kind of makes sense. I don't have access to a host at the other end to test if the reverse pattern holds true, but it would be fun to find out...
I could (will!) probably hack a test network together to figure this out more or less definitively with a bunch of Mikrotik routers which support MPLS and MPLS/VPLS and BGP-based VPLS - if you don't have a lot of money and/or an employer with a test lab, Mikrotiks let you play with a LOT of amazing tech at very low prices - go buy a bunch of RB750s and play. "Book learning" gets you quite far, but playing with things yourself really cements that knowledge, and often gives you a better "gut feel" of what is going on. Unfortunately, I can't see an icmp tunnel option, so that may reduce my ability to figure out exactly what's happening - the service provider's network is mainly Juniper and Cisco. Of course, one day, I'll probably bump into a SP engineer and say "Hey, this is odd; I understand MPLS makes the traceroutes odd and more or less what's going on there, but why does Ping do this? Is it *this* (limited customer routes on some P LSRs - less likely, because then surely it could return the TTL expired from ICMP traceroute) or *this* (pings destined to (some) P routers don't get tunneled) that explains this "odd" behaviour, or is it something else I haven't even learned about yet?".
I could (will!) probably hack a test network together to figure this out more or less definitively with a bunch of Mikrotik routers which support MPLS and MPLS/VPLS and BGP-based VPLS - if you don't have a lot of money and/or an employer with a test lab, Mikrotiks let you play with a LOT of amazing tech at very low prices - go buy a bunch of RB750s and play. "Book learning" gets you quite far, but playing with things yourself really cements that knowledge, and often gives you a better "gut feel" of what is going on. Unfortunately, I can't see an icmp tunnel option, so that may reduce my ability to figure out exactly what's happening - the service provider's network is mainly Juniper and Cisco. Of course, one day, I'll probably bump into a SP engineer and say "Hey, this is odd; I understand MPLS makes the traceroutes odd and more or less what's going on there, but why does Ping do this? Is it *this* (limited customer routes on some P LSRs - less likely, because then surely it could return the TTL expired from ICMP traceroute) or *this* (pings destined to (some) P routers don't get tunneled) that explains this "odd" behaviour, or is it something else I haven't even learned about yet?".
Exposing MPLS tunnels with traceroute options
Of course, you can also show mpls tunnels with traceroute (at least if the operator allows it) - at least in Unix style traceroute implementation, with the -e flag:
sudo traceroute -I -e -n 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets
1 10.2.255.253 14.648 ms 14.614 ms 14.609 ms
2 10.255.0.1 0.385 ms 0.378 ms 0.371 ms
3 196.21.242.161 0.511 ms 0.507 ms 0.621 ms
4 196.21.242.1 1.358 ms 1.355 ms 1.476 ms
5 155.232.5.4 <MPLS:L=24043,E=0,S=1,T=1> 35.028 ms 35.026 ms 35.083 ms
6 155.232.6.41 <MPLS:L=24196,E=0,S=1,T=1> 31.653 ms 31.443 ms 31.709 ms
7 155.232.64.68 <MPLS:L=639531,E=0,S=1,T=1> 14.075 ms 14.046 ms 14.041 ms
8 * * *
9 155.232.1.36 <MPLS:L=310480,E=0,S=1,T=1> 34.551 ms 34.390 ms 34.364 ms
10 155.232.129.17 30.850 ms 30.838 ms 30.900 ms
11 72.14.211.150 30.928 ms 30.890 ms 30.805 ms
12 72.14.239.117 34.398 ms 34.413 ms 34.451 ms
13 8.8.8.8 30.953 ms 30.739 ms 30.842 ms
2 10.255.0.1 0.385 ms 0.378 ms 0.371 ms
3 196.21.242.161 0.511 ms 0.507 ms 0.621 ms
4 196.21.242.1 1.358 ms 1.355 ms 1.476 ms
5 155.232.5.4 <MPLS:L=24043,E=0,S=1,T=1> 35.028 ms 35.026 ms 35.083 ms
6 155.232.6.41 <MPLS:L=24196,E=0,S=1,T=1> 31.653 ms 31.443 ms 31.709 ms
7 155.232.64.68 <MPLS:L=639531,E=0,S=1,T=1> 14.075 ms 14.046 ms 14.041 ms
8 * * *
9 155.232.1.36 <MPLS:L=310480,E=0,S=1,T=1> 34.551 ms 34.390 ms 34.364 ms
10 155.232.129.17 30.850 ms 30.838 ms 30.900 ms
11 72.14.211.150 30.928 ms 30.890 ms 30.805 ms
12 72.14.239.117 34.398 ms 34.413 ms 34.451 ms
13 8.8.8.8 30.953 ms 30.739 ms 30.842 ms
(the -n flag disables the reverse lookups of the IP addresses and is far more readable in this example, but they can be useful, so drop that flag if you want to). Much like with DNS (dig vs nslookup), the Unix toolset beats the pants off what's in Windows (and further compare the wonders of mtr [the e key will reveal MPLS there too] with pathping!). Interestingly, I saw different results between -I and non-I versions.
Oh look! MPLS labels! Mystery solved - definitely some MPLS tunnels - several of them (more than 2) - see the L values.
Conclusion
It kind of leaves me itching to see more of the config on the service provider's routers...
It's a jump from mid-size enterprise networking knowledge levels into large Service Provider/massive enterprise networking, but it's useful to know about! That's one thing I enjoy about networks - they're fun puzzles, and there is always more to learn. Anyway, I've learnt something new and useful about interpreting Traceroute results today, and found a satisfying answer to something that's sort of bothered me for years - maybe you have too! I'll probably come back and tweak this article as I learn more about MPLS and my understanding solidifies.
Further reading:
- https://www.nanog.org/meetings/nanog49/presentations/Sunday/mpls-nanog49.pdf - MPLS for Dummies - well worth a read as a "primer" on MPLS.
- https://www.slideshare.net/RichardSteenbergen/a-practical-guide-to-correctly-troubleshooting-with-traceroute - Correctly troubleshooting with traceroute - absolute gold!
- https://www.caida.org/publications/papers/2012/revealing_mpls_tunnels/revealing_mpls_tunnels.pdf - Research paper about detecting MPLS tunnels
- http://rtodto.net/traceroute-in-mpls-icmp-tunneling/ - Traceroute behaviour in MPLS tunneling
No comments:
Post a Comment